AI生成物へのウォーターマークについて【記事翻訳】

HuggingFace 記事の翻訳 – AI生成物に関するウォーターマーク技術とツール関連について。

目次
記事概要
- AI生成コンテンツの増加に伴い、ディープフェイクなどが問題となっており、社会的な被害を引き起こす可能性がある。
- AI生成コンテンツにウォーターマークを追加することで、その出所や真正性を示すことが可能になる。
- ウォーターマークには可視的なものと不可視的なものがあり、AI特有の課題に対応するための手法が存在する。
- コンテンツの生成段階または生成後にウォーターマークを適用する方法があり、それぞれに利点と制限がある。
- データポイズニングや署名技術を使用して、画像の非合意による操作を防ぎ、真正性を保護する。
- オープンソースとクローズドソースのウォーターマーク技術の間でバランスを取ることが、悪意ある使用を防ぐ上で重要。
- Hugging Faceは、画像、テキスト、オーディオなどの異なるデータタイプに対するウォーターマーキングのためのツールと技術を提供している。
記事本文
近月、テイラー・スウィフトの画像からトム・ハンクスの動画、そしてアメリカ合衆国大統領ジョー・バイデンの録音に至るまで、「ディープフェイク」と呼ばれるAI生成コンテンツに関する多くのニュース記事を目にしました。これらは製品を販売するため、人々の画像を本人の同意なしに操作するため、個人情報のフィッシングを支援するため、または有権者を誤解させることを意図したデマ資料を作成するために、ますますソーシャルメディアプラットフォームで共有されています。これにより、これらのコンテンツは迅速に広まり、より広範なリーチを持ち、その結果、長期にわたる被害を引き起こす可能性があります。
このブログ投稿では、AI生成コンテンツのウォーターマーキングを行うアプローチを説明し、その利点と欠点について議論し、Hugging Face Hubで利用可能なウォーターマークの追加/検出のためのいくつかのツールを紹介します。
ウォーターマーキングとは何か、そしてそれはどのように機能するのか?

ウォーターマーキングは、本物であることなどの追加情報を伝えるためにコンテンツにマークを付けるために設計された方法です。AI生成コンテンツのウォーターマークは、完全に可視的なもの(図1)から不可視的なもの(図2)までさまざまです。AIにおいて、ウォーターマーキングはデジタルコンテンツ(例えば画像)にパターンを追加し、そのコンテンツの出所に関する情報を伝えることを意味します。これらのパターンは、人間またはアルゴリズムによって認識されることができます。
AI生成コンテンツのウォーターマーキングには二つの主要な方法があります:一つ目はコンテンツ作成中に行われ、モデル自体へのアクセスが必要ですが、生成プロセスの一部として自動的に埋め込まれるため、より堅牢であるとも言えます。二つ目の方法は、コンテンツが生成された後に実装され、閉鎖ソースや独占的なモデルからのコンテンツにも適用可能ですが、全てのタイプのコンテンツ(例えば、テキスト)に適用可能とは限りません。
データポイズニングと署名技術
ウォーターマーキングに加えて、非合意による画像操作を制限する役割を果たすいくつかの関連技術があります。いくつかのツールは、オンラインで共有する画像をわずかに変更して、AIアルゴリズムがそれらをうまく処理できないようにします。人間は画像を通常通りに見ることができますが、AIアルゴリズムは比較可能なコンテンツにアクセスできず、その結果、新しい画像を作成することができません。このような画像をわずかに変更するツールには、GlazeやPhotoguardがあります。他のツールは、AIアルゴリズムのトレ
ーニングにおける前提を破壊することで画像を「毒する」ことで動作し、AIシステムがオンラインで共有された画像に基づいて人々の姿を学習することを不可能にします。これにより、これらのシステムが人々の偽画像を生成することがより困難になります。これらのツールには、NightshadeやFawkesが含まれます。
コンテンツの真正性と信頼性を維持することも、「署名」技術を利用することで可能です。これらはコンテンツを出所に関するメタデータとリンクさせます。例えばTruepicの作業は、C2PA基準に従ってメタデータを埋め込みます。画像署名は、画像の出所を理解するのに役立ちます。メタデータは編集可能ですが、Truepicのようなシステムは1) メタデータの妥当性が検証可能であることを保証する認証を提供し、2) 情報を削除することをより困難にするウォーターマーキング技術と統合することで、この制限を回避するのに役立ちます。
オープン対クローズドウォーターマーク
一般公開と非公開のウォーターマーカーおよび検出器へのアクセスレベルを提供することの利点と欠点があります。オープン性はイノベーションを促進し、開発者が主要なアイデアに取り組み、より良いシステムを作り出すことができます。しかし、悪意のある使用とのバランスを取る必要があります。AIパイプラインでウォーターマーカーを呼び出すオープンコードがある場合、ウォーターマーキングステップを削除するのは簡単です。そのパイプラインの側面がクローズドであっても、ウォーターマークが既知であり、ウォーターマーキングコードがオープンである場合、悪意のあるアクターはコードを読んで、ウォーターマーキングが機能しないように生成コンテンツを編集する方法を見つけるかもしれません。検出器へのアクセスも可能であれば、検出器が低信頼度を返すまで合成物を編集し続けることができ、ウォーターマークが提供するものを無効にすることができます。Truepicのウォーターマーキングコードはクローズドですが、コンテンツ資格情報を検証できる公開JavaScriptライブラリを提供しているなど、これらの問題に直接対処するハイブリッドオープンクローズドアプローチがあります。IMATAGのウォーターマーカーを生成中に呼び出すコードはオープンですが、実際のウォーターマーカーと検出器はプライベートです。
さまざまなデータタイプのウォーターマーキング
ウォーターマーキングは、モダリティ(オーディオ、画像、テキストなど)全体で重要なツールですが、各モダリティは独自の課題と考慮事項をもたらします。ウォーターマークの意図も同様です:トレーニングデータの使用を防ぐため、コンテンツが操作されるのを防ぐため、モデルの出力をマークするため、またはAI生成データを検出するためです。現在のセクションでは、データのさまざまなモダリティ、ウォーターマーキングに対するそれらの課題、およびHugging Face Hubで異なるタイプのウォーターマーキングを実行するために存在するオープンソースツールについて探ります。
画像のウォーターマーキング
おそらく最もよく知られているウォーターマーキングのタイプ(人間によって作成されたコンテンツとAIによって生成されたコンテンツの両方に対して)は、画像に対して行われます。トレーニングデータにタグを付けて、それに基づいて訓練されたモデルの出力に影響を与えるさまざまなアプローチが提案されています。「画像クローキング」アプローチの最もよく知られた方法は「Nightshade」であり、人間の目には知覚できない微小な変更を画像に加えることで、毒されたデータで訓練されたモデルの品質に影響を与えます。Hub には、Nightshadeを開発した同じラボによって開発されたFawkesなど、類似の画像クローキングツールがあります。これは、顔認識システムを阻止することを目的として、特に人々の画像を対象としています。同様に、Photoguardもあります。これは、例えば、それらに基づいてディープフェイクを作成するために、画像が操作されることに対するガードを目的としています。
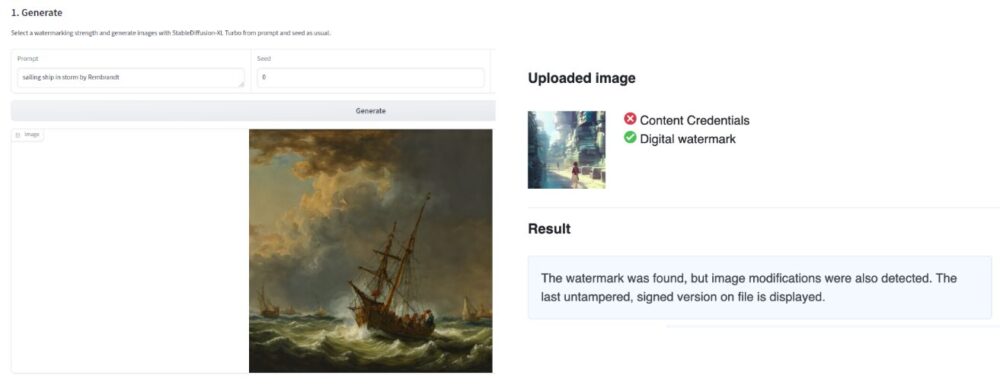
出力画像のウォーターマーキングには、Hub上で利用可能な2つの補完的なアプローチがあります。IMATAG(図2を参照)は、Stable Diffusion XL Turboなどの人気モデルの変更バージョンを活用してコンテンツの生成中にウォーターマーキングを行い、Truepicは画像が生成された後に不可視のコンテンツ資格情報を追加します。
TruePicはまた、画像自体に画像の出所と生成に関するメタデータを格納することを可能にするC2PAコンテンツ資格情報を画像に埋め込みます。IMATAGとTruePicの両方のSpacesは、それらのシステムによってウォーターマークされた画像を検出することも可能にします。これらの検出ツールはそれぞれのアプローチに固有のものであり(つまり、アプローチ固有のものです)。Hubには既存の一般的なディープフェイク検出Spaceがありますが、私たちの経験では、これらのソリューションのパフォーマンスは画像の品質と使用されたモデルによって異なることがわかりました。
テキストのウォーターマーキング
AI生成画像にウォーターマークを追加することは直感的に思えるかもしれませんが、テキストは全く異なる話です… 書かれた単語や数字(トークン)にどのようにウォーターマークを追加しますか?現在のアプローチでは、以前のテキストに基づいてサブボキャブラリーを促進することに依存しています。LLMが生成されたテキストのためにこれがどのように見えるかを詳しく見てみましょう。
生成プロセス中、LLMはサンプリングまたは貪欲デコーディングを行う前に、次のトークンのロジットのリストを出力します。以前に生成されたテキストに基づいて、ほとんどのアプローチはすべての候補トークンを2つのグループに分けます – それらを「赤」と「緑」と呼びましょう。「赤」のトークンは制限され、「緑」のグループが促進されます。これは、赤グループのトークンを完全に禁止する(ハードウォーターマーク)、または緑グループの確率を高める(ソフトウォーターマーク)ことによって行うことができます。元の確率を変更するほど、私たちのウォーターマーキングの強度が高くなります。WaterBenchは、ウォーターマーキングアルゴリズムのパフォーマンスを比較し、リンゴとリンゴの比較のためにウォーターマーキングの強度を制御するためのベンチマークデータセットを作成しました。
検出は、各トークンがどの「色」であるかを決定し、その後、入力テキストが問題のモデルから来た確率を計算することによって機能します。短いテキストはトークンが少ないため、信頼度がはるかに低いことに注意してください。
テキストウォーターマーク
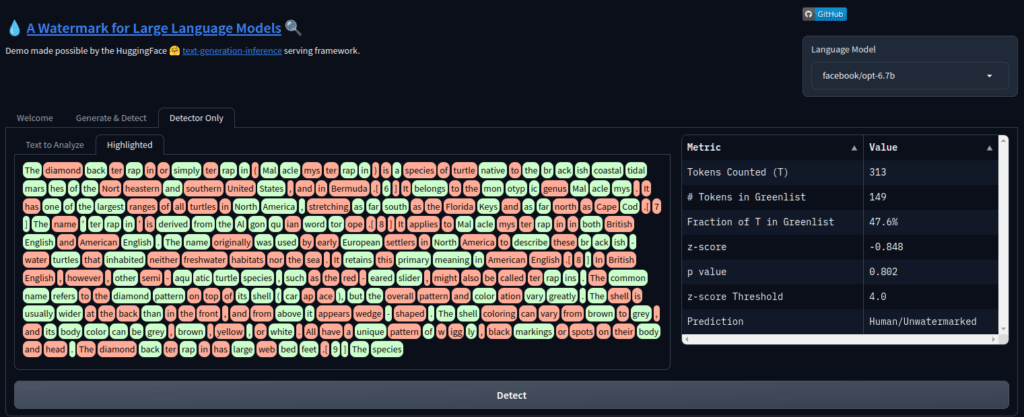
Hugging Face HubでLLMのウォーターマーキングを簡単に実装する方法がいくつかあります。LLMのためのウォーターマークSpace(図3を参照)はこれを示しており、OPTやFlan-T5などのモデルでLLMウォーターマーキングアプローチを使用しています。本番環境のワークロードの場合、同じウォーターマーキングアルゴリズムを実装し、対応するパラメータを設定するテキスト生成推論ツールキットを使用できます。これは、最新のモデルで使用できます!
AI生成画像の普遍的なウォーターマーキングと同様に、テキストの普遍的なウォーターマーキングが可能かどうかはまだ証明されていません。GLTRなどのアプローチは、異なるモデルの生成されたテキストのロジットを比較することに依存しているため、アクセス可能な任意の言語モデルに対して堅牢であることを意図しています。特定のモデルを使用して生成されたテキストかどうかを検出することは、そのモデルにアクセスできない場合(クローズドソースであるか、どのモデルが使用されたかわからない場合)は現在不可能です。
上述したように、生成されたテキストの検出方法は、信頼できるためには大量のテキストが必要です。それでも、検出器は高い偽陽性率を持ち、人間によって書かれたテキストを合成と誤ってラベル付けすることがあります。実際、OpenAIは2023年に低い精度率のために自社の検出ツールを撤回しました。これは、教師が生徒が提出した課題がChatGPTを使用して生成されたかどうかを判断するために使用したときに意図しない結果を招きました。
オーディオのウォーターマーキング
個人の声から抽出されたデータ(ボイスプリント)は、しばしば個人を識別するための生体認証セキュリティメカニズムとして使用されます。通常、PINやパスワードなどの他のセキュリティ要素と組み合わせて使用されますが、この生体認証データの侵害は依然としてリスクを示し、多くの銀行が電話で顧客を確認するために音声認識技術を使用しているため、例えば銀行口座へのアクセスに使用される可能性があります。AIで声を複製することが容易になるにつれて、音声オーディオの真正性を検証する技術も改善する必要があります。オーディオコンテンツのウォーターマーキングは、画像のウォーターマーキングと同様に、出所に関するメタデータを注入できる多次元の出力空間が使用されるという意味で似ています。オーディオの場合、ウォーターマーキングは通常、人間の耳には知覚できない周波数(約20Hz以下または約20,000Hz以上)で行われ、AI駆動のアプローチを使用して検出できます。
オーディオ出力の高いリスク性を考慮すると、オーディオコンテンツのウォーターマーキングは積極的な研究分野であり、過去数年間にわたって複数のアプローチ(例えば、WaveFuzz、Venomave)が提案されています。
AudioSealは、編集の存在下でも長いオーディオの中でウォーターマークされた断片を検出する検出器と、オーディオにウォーターマークを埋め込むジェネレータを共同で訓練する、音声のローカライズされたウォーターマーキングのための方法です。Audiosealは、自然および合成音声の両方のサンプルレベル(1/16k秒の解像度)での最先端の検出パフォーマンスを達成し、信号品質の変更を限定的にし、多くの種類のオーディオ編集に対して堅牢です。

AudioSealは、安全性のためのメカニズムを備えたSeamlessExpressiveおよびSeamlessStreamingデモのリリースにも使用されました。
結論
偽情報、合成コンテンツの生成を非難されること、および本人の同意なしに人々の不適切な表現が困難で時間がかかり、多くの場合、訂正と明確化が行われる前に多くの損害が発生します。したがって、AI生成コンテンツを迅速かつ体系的に識別するメカニズムを持つことは、Hugging Faceの使命の一部として重要です。AIウォーターマーキングは万能ではありませんが、AIの悪意ある使用と誤解を招く使用との戦いにおいて強力なツールである可能性があります。